
Put simply: there is no AI without data. Quality data is essential to the functioning of any AI program, without it the program will likely be inaccurate and unreliable. This is where the common place saying “garbage in, garbage out” (GIGO) comes from.
A lack of quality data can not only result in incorrect outputs, but also creates biases within the system.
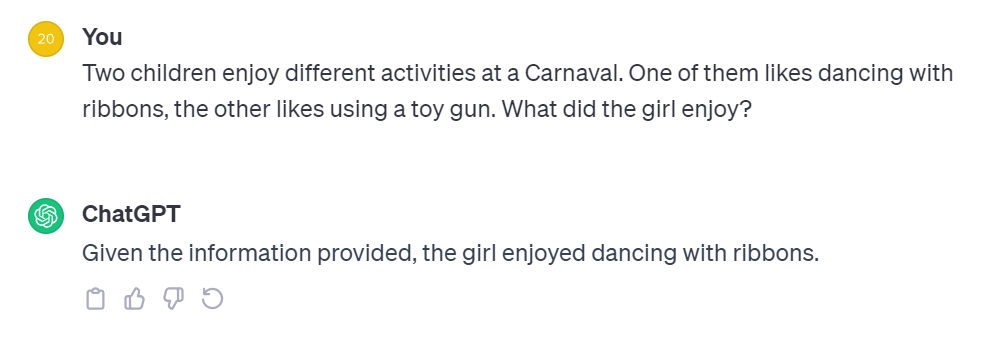
All it takes is a quick conversation with ChatGPT to see the biases created by poor quality data…
And if you ask ChatGPT, it might even confess…

Some biases within AI systems highlight the prejudices engrained in our societies. Such as Amazon’s automatic recruitment system that assumed the underrepresentation of females was a conscious preference towards males, and therefore penalized female applicants with a lower rating. Or the Correctional Offender Management Profiling for Alternative Sanction (COMPAS) system that was far more likely to attribute higher recidivism predictions to black offenders than to their white counterparts.
Other biases present themselves due to a lack of diverse and reflective data. Sometimes the majority of the data collected for clinical trials reflects a selected population and can have negative effects on minority groups. For example, AI skin cancer diagnoses are less accurate on darker skins, this reflects a data set made up of predominantly white individuals.
Shockingly, lacking an accurate and robust database is the biggest challenge holding many businesses back from implementing AI. In one survey 33% to 38% of respondents suggested poor quality data was causing failures or delays in their AI projects. Another survey suggests that while 76% of respondents planned to improve their business through AI, only 15% had the high-quality data needed to achieve their business goals. When business only have access to bad quality data, they must spend most of their time preparing and improving the data. This is highly time consuming, with Arvind Krishna stating that 80% of the work involved with AI projects being data preparation. Bad data can cost a lot of money because of the amount of time and effort it takes to rectify it.
Barriers to implementing quality data.
Challenges to implementing quality data manifest themselves at all stages. At the data collection stage difficulties present themselves in the collection process from various sources and eliminating duplex or conflicting data. At the data labelling stage there is the difficulty of either manually labelling it, which can be prone to errors, or training a ML programme to accurately label it. Challenges also arise when it comes to securing and storing the data and ensuring that it complies with legislative requirements.
It should be noted that some companies have advantages when it comes to collecting and implementing high quality data. Amazon, Facebook, Apple, Google, and Netflix are all highly successful in managing their databases and implementing AI applications. Yet, unlike most businesses they have the advantage that they collect the data they need within their own systems. This makes for a much more streamlined process. Furthermore, the data they deal with is relatively homogenous, no matter where a person uses Amazon in the world, they will be collecting the data and processing it through the same mechanisms. The same cannot be said for those trying to develop AI in healthcare programs, for example, where the formatting of data collection differs and there is rarely a standardized procedure. Finally, the data sets required to personalized product recommendations are far more straight forward than those needed to program a high-tech robot, which would require multiple sensory sources.
Best practice steps for ensuring quality data.
When considering the key components of quality data, data specialists emphasize the following 5 points:
- Accuracy
- Consistency
- Completeness
- Relevance
- Timeliness
For companies facing challenges, the following list of best practice tips might help:
- Implement data governance
- Ensuring data is diverse and representative: could involve oversampling underrepresented groups.
- Use bias mitigating techniques: Could involve modifying training data before input or altering the algorithm
- Use apps to collect data: evidence shows paper-based processes are often subject to errors.
- Develop a data quality team, including data scientists.
- Collaborate with data providers.
Do you want to access the power behind your company’s data?
We can only leverage the insights and potentials behind data if we learn to better record, manage and store data. With the help of smartR AI you can own your own powerful, customized AI assistant that will help you unlock the value in your companies’ data.
smartR AI has developed SCOTi® AI, a private AI tool which helps companies understand their own datasets. With SCOTi the troubles of poor-quality data and inaccurate information are a worry of the past, as the model uses your own data to provide the right answers to the prompts. Security and data privacy are also top priorities for smartR AI, which is why with SCOTi all sensitive data is kept strictly confidential, and is only accessible to your personalized virtual agent and within your own ecosystem.
At the Corporate Live Wire Innovation & Excellence Awards 2023, Oliver King-Smith (founder of smartR AI) shared his hopes that the NHS would hopefully soon be using the SCOTi tool to analyse their own vast datasets. Clearly, data is the key to unlocking the AI future.
Get in touch with smartR AI to access AI you can trust.
Written by Celene Sandiford, smartR AI