
smartR AI™ and EPCC, part of the University of Edinburgh, are partnering together on a super computer trial project using the Cerebras CS-2 Wafer-Scale Engine (WSE) system.
EPCC is the UK’s leading centre of Supercomputing and Data Science expertise and conducts research at the leading edge of High-Performance Computing and Data Science. The collaboration with smartR AI, a Scottish-based consultancy excelling and specializing in Natural Language Processing (NLP) applications of AI, originated through a need for comparing the performance of the EPCC’s Wafer-Scale Engine CS-2 chip with a Nvidia RTX-3090 Graphical Processing Unit (GPU) in the context of training and fine-tuning Large Language Models (LLMs). To address these issues, we have conducted a comparative analysis of the training convergence time on both processing units.
We conducted a comparison between two advanced hardware setups designed for optimized parallel computation. First, we examined the Cerebras Wafer-Scale Engine CS-2 chip, notable for its colossal compute core scale with 850,000 AI-optimized cores. This chip addresses deep learning bottlenecks by efficiently utilizing its cores and 40 GB of on-chip memory, boasting an exceptional 20 PB/s memory bandwidth. Conversely, the smartR.ai Alchemist server employs the Nvidia RTX 3090, positioning it as a promising solution for on-premise fine-tuning of Large Language Models (LLMs). To ensure fairness, we aligned CUDA and WSE core counts for direct comparison of training loss conversion performance This head-to-head analysis sheds light on parallel computation possibilities, impacting the evolution of LLMs and deep learning applications. The results are staggering, with 5x faster training loss convergence of a GPT-2 model pretraining.
In our comparison experiment, we conducted pre-training on a version of the GPT-2 model. As the original OpenAI GPT2 paper uses, we employed an open version of WebText, OpenWebText, which is an open-source recreation of the WebText corpus. The text is web content extracted from URLs shared on Reddit with at least three upvotes. (38GB).
We used a Byte-Pair Encoding (BPE) tokenizer with a vocabulary size of 50,000. However, our GPU’s hardware limitations led us to keep the context size of this dataset at 512 units. This choice helped us work within our GPU’s capabilities while still serving the purpose effectively.
In a significant research effort, we conducted a comparison by pre-training a smaller version of the GPT-2 model. We engaged in a comprehensive training process that spanned 150,000 training steps, culminating in the point where training loss was converged.
This specific version of the GPT-2 model boasts 117 million parameters and a context size of 512. Using a Byte-Pair Encoding (BPE) tokenizer with a vocabulary of 50,000 words, we maintained precision by using full float32 for model weights, which required a memory allocation of 512 megabytes. Due to the hardware limits in our GPU, we could not create a model with longer context-size which the modern LLMs have bigger than 1024.
Throughout the training process, we utilized a batch size of 16 and implemented the AdamW optimization algorithm with a learning rate of 2.8E-4, alongside a learning rate scheduler.
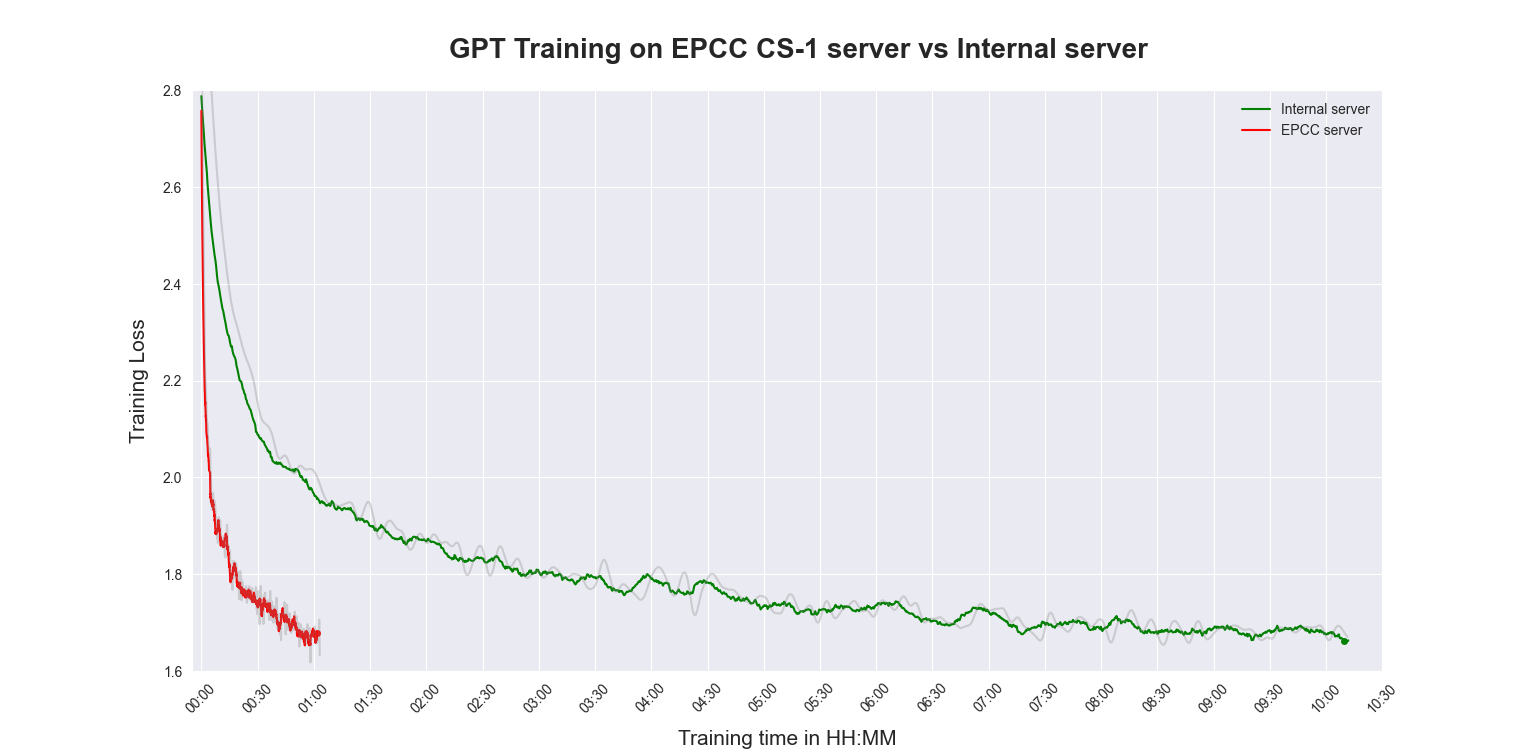
Thus far, running the sample models smartR AI has managed to train a model from scratch in nearly 1 hour on the EPCC system with the Cerebras CS-2 chip, compared to the massive 10 hours that it took to complete on their own internal system with a Nvidia RTX 3090 GPU. The company’s engineers working on this project are quite certain they will be able to utilize more resources on the EPCC’s Cerebras system and speed it up even more.
Julien Sindt, Business Development Manager at EPCC, commented on the results of phase 1 of the project: “These impressive results from smartR AI give clear confirmation of our belief that the Cerebras CS-2 is a game-changer for training large language models. The Cerebras team has recently developed new upgrades for the system which we expect will enable training times to be reduced even further. We look forward to sharing these benefits with our partners.”
The following graphic shows the results of smartR AI’s performance trial to date.
Oliver King-Smith, founder and CEO of smartR AI commented on the collaboration: “We are very fortunate to be able to work with EPCC on this important LLM and GPT related performance project, and look forward to the potential to incorporate other similar tests with, for example, the EPCC’s new Graphcore POD64 system.”
About EPCC, University of Edinburgh
Based in the University of Edinburgh, EPCC provides supercomputing and data services to industry and academia. Since our inception in 1990, we have gained an impressive reputation for leading-edge capability in all aspects of high-performance computing (HPC), data science, and novel computing. This expertise is reinforced by deep ties with industry and academia.
We have a strong track record of working with businesses, leveraging our expertise and facilities to accelerate the adoption, and spread the benefits, of high-performance computing. We operate a remarkable collection of computing and data storage facilities at our Advanced Computing Facility, including hosting the UK National Supercomputing Services ARCHER2 and Cirrus. We are a leading provider of high-performance computing and data science education and training, and conduct research at the leading edge of these fields.
About smartR AI
smartR AI augments your team with AI expertise. We work closely with all stakeholders to drive enterprise-wide implementation of AI, streamlining workflows. At smartR AI, we spend the time to learn about your business and collaborate closely with your teams to develop a customized AI solution unique to you. Our smartR team has years of experience adapting AI solutions to real world needs. We’ve developed proprietary model building blocks to accelerate the development of your project.
- For business applications we have SCOTi – your loyal AI pal.
- For medical, health and wellbeing applications, we have alertR – a behavioral intelligence-based alerting system.
We specialize in providing safe private models, that manage risk, while providing high reward. As our models are specifical trained for you, they work naturally with people to enhance and optimize productivity, and reveal previously unseen insights from your vast data pools. But most importantly, smartR is committed to providing safe AI programs within your own secure and private ecosystems.
We invent tomorrow’s products today by breaking free from pre-programmed rules. As intelligence moves to the edge of the network, smartR AI is all about doing things the smartest way. smartR AI improves your life intelligently by empowering your workforce with actionable insights.
By Matthew Malek, Engineer, smartR AI